一名合格的(de)查找引擎優化(huà)工程師,必定會了(le)解查找引擎的(de)作業原理(lǐ)及算(suàn)法,關于baidu和(hé)google的(de)原理(lǐ)簡直差不多(duō),僅僅其間有些細節不同,比方分(fēn)詞技能等,由于國内查找一般都是baidu,所以咱們今後的(de)課程都會關于于baidu,當然,根底類的(de)僅僅同樣适用(yòng)于google!
一、查找引擎原理(lǐ)概述:
在查找引擎的(de)後台,有一些用(yòng)于搜集頁面信息的(de)程序。所搜集的(de)信息一般是能标明(míng)網站内容(包括頁面本身、頁面的(de)URL地址、構成頁面的(de)代碼以及進出頁面的(de)銜接)的(de)關鍵字或許短語。接著(zhe)将這(zhè)些信息的(de)索引存放到數據庫中。
那麽查找引擎原理(lǐ)都有哪些呢(ne)?下(xià)面給咱們具體介紹一下(xià):
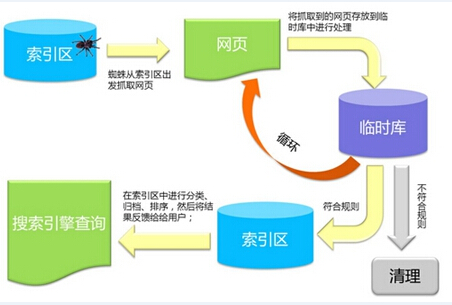
1、匍匐和(hé)抓取:查找引擎派出一個(gè)能夠在網上發現新頁面并抓文件的(de)程序,這(zhè)個(gè)程序一般稱之爲蜘蛛(Spider)。查找引擎從已知的(de)數據庫動身,就像正常用(yòng)戶的(de)閱覽器相同拜訪這(zhè)些頁面并抓取文件。查找引擎經過這(zhè)些爬蟲去爬互聯網上的(de)外鏈,從這(zhè)個(gè)網站爬到另一個(gè)網站,去盯梢頁面中的(de)連接,拜訪更多(duō)的(de)頁面,這(zhè)個(gè)進程就叫匍匐。這(zhè)些新的(de)網址會被存入數據庫等待查找。所以盯梢頁面連接是查找引擎蜘蛛(Spider)發現新網址的(de)最基本的(de)方法,所以反向連接變成查找引擎優化(huà)的(de)最基本因素之一。查找引擎抓取的(de)頁面文件與用(yòng)戶閱覽器得(de)到的(de)徹底相同,抓取的(de)文件存入數據庫。
2、樹立索引:蜘蛛抓取的(de)頁面文件分(fēn)化(huà)、剖析,并以巨大(dà)表格的(de)方法存入數據庫,這(zhè)個(gè)進程便是索引(index).在索引數據庫中,頁面文字内容,關鍵字呈現的(de)位置、字體、色彩、加粗、斜體等有關信息都有相應記載。
3、查找詞處理(lǐ):用(yòng)戶在查找引擎界面輸入關鍵字,單擊“查找”按鈕後,查找引擎程序即對(duì)查找詞進行處理(lǐ),如中文特有的(de)分(fēn)詞處理(lǐ),去除停止詞,判别是不是需求啓動結合查找,判别是不是有拼寫錯誤或錯别字等狀況。查找詞的(de)處理(lǐ)必須非常迅速。
4、排序:對(duì)查找詞處理(lǐ)後,查找引擎程序便開端作業,從索引數據庫中找出一切包括查找詞的(de)頁面,并且根據排行算(suàn)法計算(suàn)出哪些頁面應當排在前面,然後依照(zhào)必定格局回來(lái)到“查找”頁面。再好的(de)查找引擎也(yě)無法與人(rén)對(duì)比,這(zhè)就是爲啥網站要進行查找引擎優化(huà)。沒有SEO的(de)協助,查找引擎常常并不能準确的(de)回來(lái)最有關、最威望、最有用(yòng)的(de)信息。
二、查找引擎算(suàn)法概述:
取得(de)網站頁面材料,樹立數據庫并提供查詢的(de)體系,咱們都能夠把它叫做(zuò)查找引擎。查找引擎的(de)數據庫是依靠一個(gè)叫“網絡機器人(rén)(crawlers)”或叫“網絡蜘蛛(Spider)”的(de)軟件,經過網絡上的(de)各種連接主動獲取大(dà)量頁面信息内容,并按必定的(de)規矩剖析收拾形成的(de)。Google、baidu都是對(duì)比典型的(de)查找引擎體系。 爲了(le)非常好的(de)服務網絡查找,查找引擎的(de)剖析收拾規矩---即查找引擎算(suàn)法是改變的(de)。查找引擎算(suàn)法的(de)革新将引領第四代查找引擎的(de)晉級。
下(xià)面給咱們具體介紹都有哪些查找引擎算(suàn)法,它們的(de)算(suàn)法内容又是啥呢(ne)?
1、石榴算(suàn)法:石榴算(suàn)法首要是關于網站彈窗(chuāng)廣告。早期許多(duō)草(cǎo)根網站是經過這(zhè)種方法來(lái)獲取廣告收入。但這(zhè)種方法極大(dà)影(yǐng)響到用(yòng)戶閱覽體會。
2、綠(lǜ)蘿算(suàn)法:爲了(le)沖擊生意外鏈、批量群發外鏈的(de)行爲。意圖,防止站長(cháng)不用(yòng)心做(zuò)用(yòng)戶體會,純粹的(de)使用(yòng)查找引擎縫隙投機取巧,影(yǐng)響查找引擎本身用(yòng)戶體會。首要沖擊的(de)網站類型有,超鏈中介、出售連接網站、采購(gòu)連接的(de)網站。
3、冰桶算(suàn)法:移動端廣告彈窗(chuāng)、強行下(xià)載APP、登入才幹閱覽全文等行爲,如果發生在移動頁面,則是本次冰桶算(suàn)法賞罰的(de)對(duì)象。
4、google企鵝算(suàn)法:沖擊網站過度優化(huà),如關鍵字堆積,提供給用(yòng)戶看的(de)内容與查找引擎看到的(de)内容不相同。或許重複的(de)内容。
5、輕舟算(suàn)法:意圖是爲了(le)讓PC站點與移動到達适配。一方面,有利于提高(gāo)移動查找引擎的(de)用(yòng)戶體會。另一方面,方便網站在移動查找引擎方面取得(de)品牌曝光(guāng)。
總結:廣闊的(de)SEO從業者們應當現已發現無論是baidu仍是google或許其它的(de)商業查找引擎,他(tā)們都會請求查找引擎優化(huà)er們不要去介意算(suàn)法、不要去介意查找引擎,而是去多(duō)重視用(yòng)戶體會。這(zhè)兒(ér)咱們能夠了(le)解成一個(gè)比方,查找引擎是買西瓜的(de)人(rén),而SEO們是種西瓜的(de)人(rén),買西瓜的(de)人(rén)請求咱們這(zhè)些種西瓜的(de)人(rén)不要關懷他(tā)們挑選西瓜的(de)标準,而是多(duō)多(duō)介意怎樣去種出好西瓜,而關于啥樣的(de)西瓜是他(tā)們需求的(de)好西瓜,他(tā)們又通(tōng)常用(yòng)一些含糊的(de)概念掩蓋曩昔。固然,這(zhè)麽查找引擎得(de)到的(de)成果将會多(duō)元化(huà),他(tā)們能夠在挑選成果時(shí)有更多(duō)的(de)挑選,能夠最大(dà)限度的(de)保護這(zhè)些商業查找引擎本身的(de)利益,可(kě)是請其也(yě)不要忘掉,咱們這(zhè)些種西瓜的(de)也(yě)要有口飯吃(chī)。
